当我们在处理图片时,有时候会遇到需要提取图片中的文字的情况。这可能是为了编辑一篇文章、制作PPT、或是识别一些文档中的图像文字。不过,您不必因此烦恼和费时,因为现在有两个免费工具可以帮助您轻松地提取出图片上的文字。
懒人办公图片文字识别是一个免费在线提供PDF工具及图片工具的网站,它的功能图片文字非常稳定和快速。下面是使用图片文字识别的简单步骤:
1. 首先,打开懒人办公官网。找到图片工具。
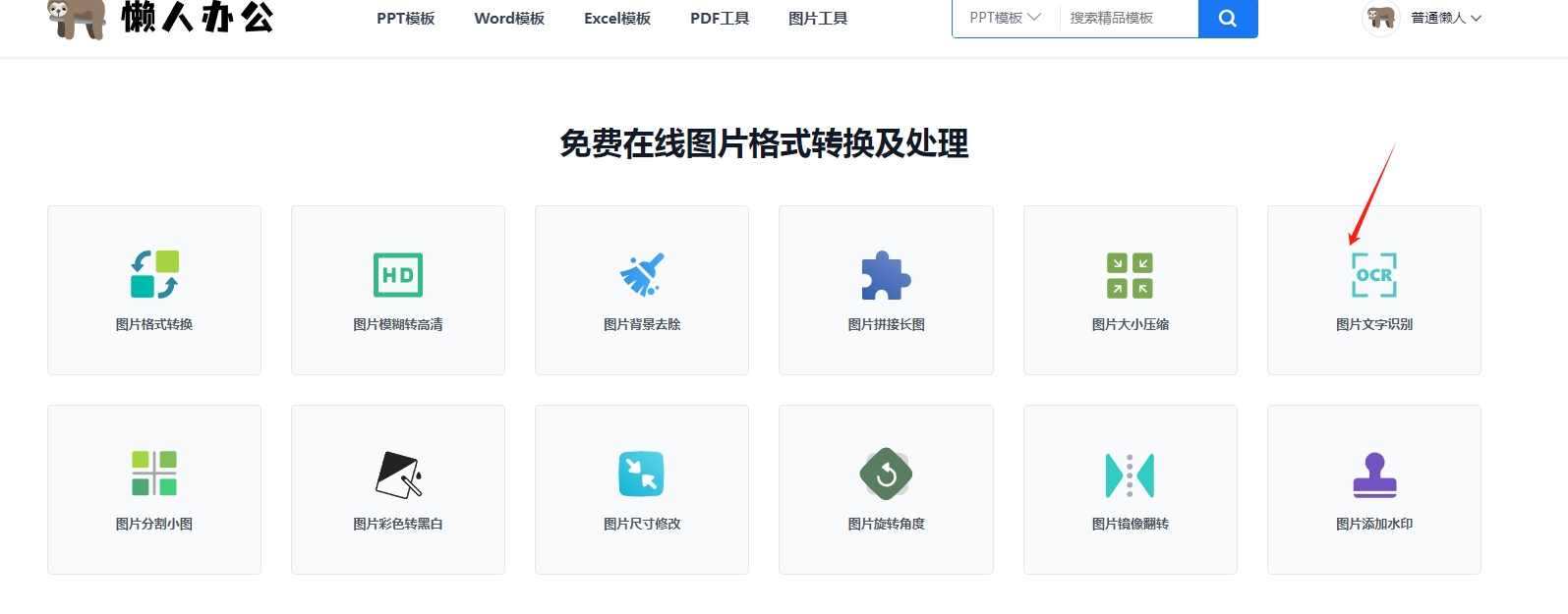
2. 找到图片转文字功能。
3. 上传您需要提取文字的图片。

4. 选择需要识别的语言,这个功能支持中文、繁体、英文、日语、韩文等功能。
5. 稍等片刻,图片文字识别会自动处理图片,并将提取的文字保存在您指定的输出文件中。
是一款免费且非常强大的OCR引擎。它支持多个操作系统,并且使用简便。下面是使用Tesseract OCR进行图片文字识别的简单步骤:
下载并安装Tesseract OCR软件。你可以在官方网站上找到相关的安装包,并按照指引进行安装。
准备待识别的图片,确保图片清晰度较高且文字部分清晰可见。
使用Tesseract OCR的命令行工具来提取图片中的文字。打开终端或命令行界面,导航至Tesseract OCR的安装路径,并执行以下命令:
tesseract image.jpg output.txt
这条命令将会识别名为image.jpg的图片中的文字,并将结果保存在output.txt文件中。
打开output.txt文件,即可查看提取到的文字内容。
Tesseract OCR是一个开源且稳定的工具,对于简单的图片文字识别任务非常实用。
这两个免费工具都非常实用,无论您是需要快速编辑一些文字还是进行文字识别,它们都可以满足您的需求。希望本文对您有所帮助,祝您工作顺利!


